| Oracle Context Option Administrator's Guide | Library |
Product |
Contents |
Index |
| Oracle Context Option Administrator's Guide | Library |
Product |
Contents |
Index |
![]()
![]()
The following topics are discussed in this chapter:
The personality mask for a ConText server determines which operations the server can process.
For more information about personality masks, see "Personality Masks" in "Administration Concepts (Chapter 1)."
Instead, ConText servers with the Loader personality regularly scan a document repository (i.e. operating system directory) for documents to be loaded into text columns for indexing.
If a file is found in the directory, the contents of the file are automatically loaded by the ConText server into the appropriate table and column.
For more information about text loading using ConText servers, see "Text Loading" in this chapter.
DDL operations are requested through the administration tool or the CTX_DDL package.
In addition, the system can be configured so DML requests in the queue are processed immediately or in batch mode.
In some cases, an application developer may not want DML Queue notification to happen automatically, in which case the trigger can be deleted for the table.
DML operations may be called manually using the CTX_DML.REINDEX procedure, which places a request in the DML Queue for a specified document.
In this mode, an index is only briefly out of synchronization with the last insert, delete, or update that was performed on the table; however, immediate DML processing can use considerable system resources and create index fragmentation.
To start DML processing, the CTX_DML.SYNC procedure is called. This procedure batches all the pending requests in the queue and sends them to the next available ConText server with a DDL personality. Any DML requests that are placed in the queue after SYNC is called are not included in the batch. They are included in the batch that is created the next time SYNC is called.
SYNC can be called with a level of parallelism. The level of parallelism determine the number of batches into which the pending requests are grouped. For example, if SYNC is called with a parallelism level of two, the pending requests are grouped into two batches and the next two available DDL ConText servers process the batches.
Calling SYNC in parallel speeds up the updating of the indexes, but can increase the degree of index fragmentation.
After index creation completes, the entries are picked up by the next available DML ConText server and the index is updated to reflect the changes. This avoids a race condition in which the DML Queue request might be processed, but then overwritten by index creation, even though the index creation was processing an older version of the document.
Note: Theme queries are only supported for English-language text.
ConText Option supports three methods for text and theme queries:
For more information about text columns, see "Text Columns" in this chapter.
For more information about text and theme queries, see Oracle ConText Option Application Developer's Guide
The user then executes a SQL statement on the result table to return the list of documents (hitlist) or some subset of the documents.
The results generated by CONTAINS are returned through the SELECT clause of the SQL statement.
The user opens a CONTAINS cursor to the query buffer in memory, executes a text query, then fetches the hits from the buffer, one at a time.
The results of an SQE are stored in an internal table in the index (text or theme) for the text column. The SQE definition is stored in a system-wide, internal table owned by CTXSYS. The SQE definitions can be accessed through the views, CTX_SQES and CTX_USER_SQES.
For more information about the SQE result table, see "SQR Table" in "ConText Index Tables and Indexes (Appendix C)."
For more information about the SQE views, see "ConText Data Dictionary Views (Appendix B)."
The Linguistic Services currently provide two services for English-language documents stored in an Oracle database:
For more information about themes and Gists, as well as using the Linguistic Services in applications, see Oracle ConText Option Application Developer's Guide
Text columns can be any of the supported Oracle datatypes; however, text columns are usually one of the following datatypes:
For more information about policies and text columns, see "Policies" in "Understanding the ConText Data Dictionary (Chapter 4)."
When a policy is defined for a column, the textkey for the column is specified.
During policy definition, the primary/unique key columns are specified, using a comma to separate each column name.
In two-step queries, the columns in a composite textkey are returned in the order in which the columns were specified in the policy.
In an in-memory queries, the columns in a composite textkey are returned in encoded form (e.g. 'P1,P2,P3'). This encoded textkey must be decoded to access the individual columns in the textkey.
For more information about encoding and decoding composite textkeys, see Oracle ConText Option Application Developer's Guide
Note: There are some limits to composite textkeys that must be considered when setting up your tables and columns, and when creating policies for the columns.
Because the comma separators are included in this limit, the actual limit is 256 minus (no. of columns minus 1), with a maximum of 241 characters (256 - 15), for the combined length of all the column names in the textkey.
This limit is enforced during policy creation.
For a given row, ConText Option concatenates all of the values from the columns that constitute the composite textkey into a single value, using commas to separate the values from each column.
As such, the actual limit for the lengths of the textkey columns is 256 minus (no. of columns minus 1), with a maximum of 241 characters (256 - 15), for the combined length of all the columns.
Note: If you allow values that contain commas (i.e dates) in your textkey columns, the commas are escaped automatically by ConText Option during indexing. The escape character is the backslash character.
In addition, if you allow values that contain backslashes (i.e. dates or directory structures in Windows), ConText Option uses the backslash character to escape the backslashes.
As a result, when calculating the limit for the length of columns in a composite textkey, the overall limit of 256 (241) characters must include the backslash characters used to escape commas and backslashes contained in the data.
For more information about building text loading capabilities into your applications, see Oracle ConText Option Application Developer's Guide.
For more information about INSERT and SQL, see "Oracle7 Server SQL Reference"
For more information about SQL*Loader, see "Oracle7 Server Utilities"
The ctxload utility loads text from a load file into a specified database table. The load file can contain multiple documents, but must use a defined structure and syntax.
In addition, the load file can contain ASCII text or it can contain pointers to separate files containing ASCII text or formatted text.
Note: ctxload is best suited for loading text that you want to store in a table using direct data store. If you want to use the external data store (i.e. the OSFILE or URL Tile) to store file pointers in the database, it is possible to use ctxload; however, you should use another loading method, such as SQL*Loader.
For more information, see "Using ctxload with External Data Store Columns" in "Executables and Utilities (Chapter 8)."
If a ConText server is running with the Loader personality, it regularly checks all the sources that have been defined for columns in the database, then scans specified directories for new files. When a new file appears, it calls ctxload to load the contents of the file into the appropriate column.
When loading of the file contents is successful, the server deletes the file to prevent the contents from being loaded again.
To ensure that the files are in the correct format, a user-defined translator can be specified as one of the preferences in the source for the column.
A user-defined translator is any program that accepts a plain ASCII text file as input and generates a formatted, ASCII text load file for ctxload as its output. The user-defined translator could also be used to perform pre-loading cleanup and spell-checking of your text.
After the contents of the load file have been successfully loaded into the column, the load file generated by the translator is deleted along with the original input file to prevent the contents from being loaded again.
Note: The tables illustrated in the following sections are examples only. The column names and definitions for actual tables used to store text will vary depending on the needs of your application.
The following example illustrates a table in which text is stored directly in a column:
Table: DIRECT_TEXT
Columns: TEXTKEY NUMBER (primary or unique key)
TEXTDATE DATE
AUTHOR VARCHAR2(50)
NOTES VARCHAR2(2000) (text column with
direct torage)
TEXT LONG (text column with direct storage)The requirements for storing text directly in a column are relatively straightforward. The text is physically stored in a text column and the policy for the text column contains a Data Store preference that utilizes the DIRECT Tile.
Suggestion: If text is stored as external text in a column, the column should be be either a CHAR or VARCHAR2 column. LONG and LONG RAW columns are best suited for documents stored internally in the database.
The pointer can be either:
Table: EXTERNAL_TEXT
Columns: TEXTKEY number (primary or unique key)
TEXTDATE date
AUTHOR VARCHAR2(50)
NOTES VARCHAR2(2000) (text column with
direct text storage)
TEXT VARCHAR2(100) (text column storing
OS file name)The only difference between a table used to store text internally and externally would be the datatype of the text column. In an external table, the text column would typically be assigned a datatype of VARCHAR2, rather than LONG, because the column contains a pointer to a file rather than the contents of the file (which would require more space to store).
However, there are additional requirements for storing text externally due to the different methods (file names and URLs) of accessing text stored in flat files.
For more information about the requirements for storing text externally, see "External Text" in this chapter.
The text column used for storing text in a master/detail relationship can be in a single table or in master/detail tables. In a single table configuration, the table contains a textkey column to identify the document and a line number column to identify each segment of the document.
In a two table configuration, the master table contains the textkey column and the detail table contains the line number column and a foreign key to the textkey column in the master table.
In either configuration, the textkey and the line number columns comprise the primary key for the table used to store the text.
The following example illustrates a two table configuration that could be used for storing text in a master-detail relationship:
Table: MD_HEADER
Columns: TEXTKEY NUMBER (primary or unique key)
TEXTDATE DATE
AUTHOR VARCHAR2(50)
Table: MD_TEXT
Columns: TEXTKEY NUMBER (foreign key to
MD_HEADER.TEXTKEY)
LINE_NUM NUMBER (unique identifier for text
column -- TEXTKEY and LINE_NUM are
primary key)
TEXT VARCHAR2(80) (text column
with direct text storage)
Note: If the preference does not contain the directory path for the files, ConText Option requires the directory path to be included as part of the file name stored in the text column.
Note: Text that contains HTML tags and is stored directly in a text column is considered internal text. As such, the Data Store preference for the text column policy would use the DIRECT or MASTER DETAIL Tiles.
In addition, Web files can be any format supported by the World Wide Web, including HTML files, plain ASCII files, and proprietary formats such as PDF and Word. The filter for the column must be able to recognize and process any of the possible documents formats that may be encountered on the Web.
A URL consists of the protocol for accessing the Web file and the address of the file, in the following format:
protocol://file_address
The ConText Option URL data store supports two protocols:
For example:
http://my_server.com/welcome.html
http://www.oracle.com
Note: The file address may also (optionally) contain the port on which the Web server is listening.
A Web server is any machine that uses HTTP to accept requests for files and transfer the files to the requestor.
With HTTP, the URL data store can be used to index files in an intranet, as well as files on any publicly-accessible Web servers on the World Wide Web.
Intranets are private, company-wide networks that use the Internet to link machines in the network, but are protected from public access on the Internet via a gateway proxy server which acts as a firewall.
For security reasons, access to an intranet is generally restricted to machines within the firewall; however, machines in an intranet can access the World Wide Web through the gateway server if they have the appropriate permission and security clearance.
For example:
file://private/docs/html/intro.html
The file referenced by a URL using the file protocol must reside locally on a file system that is accessible to the machine running ConText Option.
Because the file is accessed through the operating system, the machine on which the file is located does not need to be configured as a Web server. However, the same requirements that apply to text stored as file names apply to text stored as URLs which use the file protocol.
If the requirements are not met, ConText Option returns one or more error messages.
For more information, see "Text Stored as File Names" in this chapter
For a complete list of the error messages returned by the URL data store, see Oracle ConText Option Messages.
In addition, a sub-string of host or domain names can be specified which identify machines internal to a firewall. Access to these machines do not require a proxy.
To prevent this type of bottleneck, the URL data store supports multi-threading. With multi-threading, while one thread is blocked, waiting to communicate with a Web server, another thread can retrieve a document from another Web server.
The URL Tile supports specifying the number of simultaneous threads allowed for a text column.
To allow control over the length of time an application waits for a response to an HTTP request for a URL, the URL Tile supports specifying a maximum timeout.
The URL data store returns error messages for the following exceptions:
Regardless of the format, ConText Option requires text to be filtered for the purposes of:
ConText Option also provides the ability to store multiple document formats in a column.
Note: For non-English and non-Japanese documents that contain HTML tags, an external filter must be used.
For English and Japanese text with HTML tags, the HTML filter processes all text that is delimited by the standard HTML tag characters (angle brackets).
All HTML tags are either ignored or converted to their representative characters in the ASCII character set. This ensures that only the text of the document is processed during indexing or by the Linguistic Services.
Note: For Japanese, Korean, and Chinese formatted text, external filters must be used.
The filters extract plain, ASCII text from a document, then pass the text to ConText Option, where the text is indexed or processed through the Linguistic services.
The following document formats are supported by the internal filters:
| Format | Version |
| AMIPRO for Windows | 1, 2, 3 |
| Lotus 1-2-3 for DOS | 4, 5 |
| Lotus 1-2-3 for Windows | 2, 3, 4, 5 |
| Microsoft Word for Windows | 2, 6.x, 7.0 |
| Microsoft Word for DOS | 5.0, 5.5 |
| Microsoft Word for MAC | 3, 4, 5.x |
| Word Perfect for Windows | 5.x, 6.x |
| Word Perfect for DOS | 5.0, 5.1, 6.0 |
| Xerox XIF for UNIX | 5, 6 |
Note: Of the document formats listed above, only the following formats support WYSIWYG viewing in the Windows 32-bit viewer (OCX):
Microsoft Word for Windows 2 and 6.x
Word Perfect for DOS 5.0, 5.1, 6.0
Word Perfect for Windows 5.x, 6.x
However, plain (ASCII) text also can be viewed in the 32-bit viewer.
For more information about the 32-bit viewer, see Oracle ConText Option Application Developer's Guide.
An external filter that outlines the paragraph boundaries according to ConText Option standards could be created to ensure that the Linguistic Services are provided with an ordered, logical text feed.
Note: External filters do not support WYSIWYG viewing in the Windows 32-bit viewer (OCX).
For more information about the 32-bit viewer, see Oracle ConText Option Application Developer's Guide.
If the document is in a proprietary format, the program must recognize the format tags for the document and be able to convert the formatted text into ASCII text.
In addition, the program must be an executable that can be run from the command-line and accepts two arguments:
Note: These external filters are not shipped on the Oracle7 Server/ConText Option product CD. They are shipped on a separate CD that is included in your distribution.
For more information about creating Filter preferences, see "Managing Preferences" in "Setting Up and Managing Text (Chapter 5)."
| Format | Version |
| AMIPRO for Windows | 1, 2, 3 |
| ASCII | N/A |
| HTML | 1, 2, 3 |
| Lotus 1-2-3 for DOS | 4, 5 |
| Lotus 1-2-3 for Windows | 2, 3, 4, 5 |
| Microsoft Word for Windows | 2, 6.x |
| Microsoft Word for DOS | 5.0, 5.5 |
| Microsoft Word for MAC | 3, 4, 5.x |
| Word Perfect for Windows | 5.x, 6.x |
| Word Perfect for DOS | 5.0, 5.1, 6.0 |
| Xerox XIF for UNIX | 5, 6 |
During filtering, ConText Option recognizes whether a format uses the internal or external filters and calls the appropriate filter.
Note: If required, internal filters can be overridden in a Filter preference by explicitly calling an external filter for the format. This can be useful if you have an external filter that provides additional filtering not provided by the internal filters.
For example, you may have MS Word documents that you want spellchecked before indexing. You could create an external MS Word filter that performs the spellchecking and specify the external filter in the Filter preference for the column policy.
A text index is basically an inverted index, consisting of:
For more information about the tables used to store the text index, see "Text Index Tables" in this chapter.
Each document in the text column is retrieved and filtered by ConText Option. Then, the tokens (words) are identified and extracted from the filtered text and stored in memory, along with the document ID and locations for each word, until all of the documents in the column have been processed or the memory buffer is full.
The index entries, consisting of each indexed word and its location string, are then written to the text index tables as individual rows and the buffer is flushed.
If the buffer fills up before all of the documents in the text column have been processed, ConText Option writes the index entries to the text index tables and retrieves the next document from the text column to continue text indexing.
The amount of memory allocated for text indexing for a text column determines the size of the memory buffer and, consequently, how often the text index entries are written to the text index tables.
For more information about the effects of frequently writing to the text index tables, see "Text Index Fragmentation" and "Memory Allocation" in this chapter.
The termination stage only starts when the population stage has completed for all of the documents in the text column.
In addition, ConText Option automatically creates one or more Oracle indexes for each text index table.
For a description of the text index tables, see "ConText Index Tables" and "SQR Table" in "ConText Index Tables and Indexes (Appendix C)."
For more information about stored query expressions, see Oracle ConText Option Application Developer's Guide
The tablespace, storage clause, and other parameters used to create the text index tables and Oracle indexes are specified by the attributes set for the Engine preference in the policy for the text column.
For more information about the Engine attributes, see "Tiles, Tile Attributes, and Attribute Values" in "ConText Data Dictionary (Chapter 9)."
If all the documents (rows) in a text column haven't been indexed when the text index entries are written to the text index tables, the text index entry for a word may not included all of the documents in the column. If the same word is encountered again as text indexing continues, a new text index entry for the word is stored in memory and written to the text index table when the buffer is full.
As a result, a word may have multiple rows in the text index table, with each row representing a text index fragment. The aggregate of all the rows for a word represents the complete text index for the word.
If a large amount of text is being indexed, the text index can be very large, resulting in more frequent inserts of the index text strings to the tables. By allocating more memory, fewer inserts of text index strings to the tables are required, resulting in faster text indexing and fewer text index fragments.
For more information about allocating memory for text indexing, see "Managing Preferences" in "Setting Up and Managing Text."
To perform text indexing in parallel, you must start two or more ConText servers (each with the DDL personality) and you must correctly allocate text indexing memory.
The amount of allocated index memory should not exceed the total memory available on the host machine(s) divided by the number of ConText servers performing the parallel text indexing.
For example, say you allocate 10 Mb of memory in the policy for the text column for which you want to create a text index. If you want to use two servers to perform parallel text indexing on your machine, you should have at least 20 Mb of memory available during indexing.
Note: When using multiple ConText servers to perform parallel text indexing, the servers can run on different host machines if the machines are able to connect to the database where the text index is stored.
However, updating the text index for modified/deleted documents affects every row that contains references to the document in the text index. Because this can take considerable time, ConText Option utilizes a deferred delete mechanism for updating the text index for modified/deleted documents.
In a deferred delete, the document references in the text index table (DR_nnnnn_I1Tn) for the modified/deleted document are not actually removed. Instead, the status of the document is recorded in the text index control table (DR_nnnnn_LST), so that the ID for the document is not returned in subsequent text queries that would normally return the document.
Actual deletion of the document references from the I1T table takes place only during optimization of a text index.
Garbage collection updates the text index strings to accurately reflect the status of deleted and modified documents.
ConText Option provides two methods of text index compaction:
Two-table compaction is faster than in-place compaction; however, it requires enough tablespace to be available during compaction to accommodate the creation and population of the second text index table.
Similar to index fragment compaction, ConText Option supports in-place or two-table actual deletion.
In general, optimize an index after:
Note: Theme indexing is only supported for English-language text.
The theme lexer analyzes text at the sentence, paragraph, and document level to create a context in which the document can be understood. It uses a mixture of statistical methods and hueristics to determine the main topics that are developed over the breadth of the document.
It also uses the ConText Option Knowledge Catalog, a collection of over 200,000 words and phrases, organized into a conceptual hierarchy with over 2,000 categories, to generate its theme information.
A number of predefined setting configurations are provided by ConText Option to allow users to tailor the output of the linguistic core to the style and content of their documents.
In addition, custom setting configurations can be created using the ConText Option administration tool.
Note: Since the settings can affect the themes that are generated for a document, once a theme index has been created for a column, the settings should not be altered.
If the settings are altered, the results generated for incremental changes to existing documents, as well as new documents, may be inconsistent with the results generated for the initial index creation. In this event, the theme index for the column should be dropped and the entire column reindexed to account for the new settings.
For more information about creating custom setting configurations, see the ConText Option administration tool.
For more information about setting the linguistic settings, see Oracle ConText Option Application Developer's Guide.
Note: Offset and frequency information are not relevant in a theme query, so this type of information is not stored in theme indexes.
ConText Option uses the theme signature for a document to find documents that match the themes in a theme query.
In addition, these phrases may be common terms or they may be the names of companies, products, and fields of study as defined in the Knowledge Catalog.
As such, theme indexes may contain words and phrases in uppercase, lowercase, and mixed-case.
For example, a document about Oracle contains the phrase Oracle Corp.. In the text index for the document, this phrase would have two entries, all in lowercase. In the theme index for the document, the entry would be Oracle Corporation, which is the form stored in the Knowledge Catalog.
Once a theme index is created for the policy, any text requests, including queries, on the policy will result in the theme index being accessed.
For more information about creating a theme indexing policy, see "Creating a Theme Indexing Policy" in "Setting Up and Managing Text (Chapter 5)."
For more information about theme queries, see Oracle ConText Option Application Developer's Guide.
Theme indexes are processed identically to text indexes, meaning that DDL requests for index creation and optimization are processed by any currently available DDL servers.
Similarly, theme indexes do not have to be manually updated. All DML requests are processed automatically by any DML servers that are running at the time.
When two indexes exist for the same column, one-step queries (theme or text) require the policy name to be specified as part of the CONTAINS function. In this way, the correct index is accessed for the query.
This requirement is not enforced for two-step and in-memory queries, because they use policy name, rather than column name, to identify the column to be queried.
If any of the ConText server processes are started using the ctxsrvx executable, which does not initialize the ConText Option linguistics, theme indexing and theme querying may fail.
For more information about starting ConText servers and specifying personalities, see "Managing ConText Servers" in "Administering ConText Option (Chapter 2)."
For more information about ctxsrv/ctxsrvx, see "ctxsrv/ctxsrvx Executable" in "Utilities and Executables (Chapter 8)."
If base-letter conversion is enabled for the Lexer preference in a policy, during text indexing of the column for the policy, all characters containing diacritical marks are converted to their base form in the text index. The original text is not affected.
Base-letter conversion requires that the database character set is a subset of the NLS_LANG character set. For example, suppose the NLS_LANG parameter is set to French_France.WE8ISO8859P1 and the following piece of text is to be converted to its base-letter representation:
La référence de session doit être égale à 'name'.
The words of this sentence are indexed under the entries:
la
reference
de
session
doit
etre
egale
a
name
Note: Base-letter conversion requires that the language component for NLS_LANG is set to a language (e.g. French, German) that supports an extended (8-bit) character set. In addition, the charset component must be set to one of the 8-bit character sets (e.g. WE8ISO8859P1).
Note: Base-letter conversion works with all of the query operators (logical, control, expansion, thesaurus, etc.), except the STEM expansion operator.
For more information about text queries and the query operators, see Oracle ConText Option Application Developer's Guide.
Oracle ConText Option enables users to create ISO-2788 compliant thesauri which define relationships between lexically equivalent words and phrases. Users can then retrieve documents that contain relevant text by expanding queries to include similar or related terms as defined in a thesaurus.
Note: ConText Option supports creating multiple thesauri; however, only one thesaurus can be used at a time in a query.
Three types of relationships can be defined for terms (words and phrases) in a thesaurus:
In addition, each entry in a thesaurus can have scope notes associated with it.
For example, in the synonym rings shown in Figure 3 - 2, the terms car, auto, and automobile are all synonymous. Similarly, the terms main, principal, major, and predominant are all synonymous.
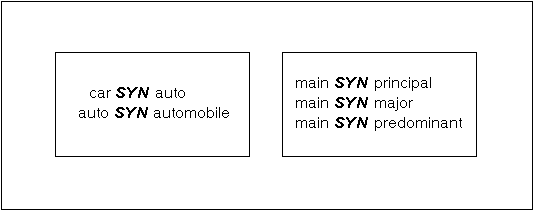 Figure 3 - 1. Synonym Rings in a Thesaurus
Figure 3 - 1. Synonym Rings in a Thesaurus
Note: A thesaurus can contain multiple synonym rings; however, synonym rings are not named. A synonym ring is created implicitly by the transitive association of the terms in the ring.
As such, a term cannot exist twice within the same synonym ring or within more than one synonym ring in a thesaurus.
Each synonym ring can have one, and only one, term that is designated as the preferred term. A preferred term is used in place of the other terms in a synonym ring when one of the terms in the ring is specified with the PT operator in a query.
Note: A term in a preferred term (PT) query is replaced by, rather than expanded to include, the preferred term in the synonym ring.
For example, in the tree structure shown in Figure 3 - 2, the term elephant is a narrower term for the term mammal. Conversely, mammal is a broader term for elephant. The top term is animal.
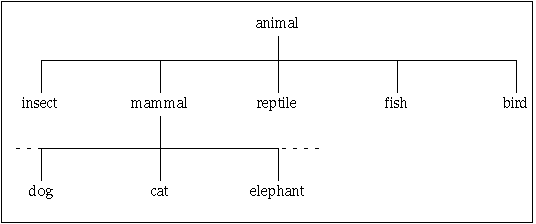 Figure 3 - 2. Narrower and Broader Thesaurus Term Hierarchy
Figure 3 - 2. Narrower and Broader Thesaurus Term Hierarchy
ConText Option also supports the following hierarchical relationships in thesauri:
Note: The three types of hierarchical relationships are optional. Any of the three hierarchical relationships can be specified for a term.
For example, the terms rat and rabbit can be specified as generic narrower terms for rodent.
For example, the provinces of british columbia and quebec can be specified as partitive narrower terms for canada.
If a term exists more than once as a narrower term in a branch, broader term queries for the term are expanded to include all of the broader terms for the term.
If a term exists more than once as a broader term in a branch, narrower term queries for the term are expanded to include the narrower terms for each occurrence of the broader term. of the the broader term for the entry is specified in an NT query, the query is expanded to include the narrower term.
For example, C is a narrower generic term for both A and B. D and E are narrower generic terms for C. In queries for terms A, B, or C, the following expansions take place:
NTG(A) expands to {C}, {A}
NTG(B) expands to {C}, {B}
NTG(C) expands to {C}, {D}, {E}
BTG(C) expands to {C}, {A}, {B}
Note: The same expansions hold true for standard and partitive hierarchical relationships.
For example, the term spring has different meanings relating to seasons of the year and mechanisms/machines. The term could be qualified in the hierarchy by the terms season and machinery.
To differentiate between the terms during a query, the qualifier can be specified. Then, only the terms that are broader terms, narrower terms, or related terms for the term and its qualifier are returned. If no qualifier is specified, all of the related, narrower, and broader terms for the terms are returned.
Note: In thesaural queries that include a term and its qualifier, the qualifier must be escaped, because the parentheses required to identify the qualifier for a term will cause the query to fail.
If a term that has one or more related terms defined for it is specified in a related term query, the query is expanded to include all of the related terms.
For example, B and C are related terms for A. In queries for A, B, and C, the following expansions take place:
RT(A) expands to {A}, {B}, {C}
RT(B) expands to {A}, {B}
RT(C) expands to {C}, {A}
Note: Terms B and C are not related terms and, as such, are not returned in the expansions performed by ConText Option.
Scope notes can be used to provide descriptions or comments for the entry.
ConText Option provides both a PL/SQL interface (CTX_THES) and a GUI administration tool for viewing, creating, updating, and deleting thesauri.
Note: Thesauri can be created, updated, and deleted by all users with the CTXAPP role.
In addition, the ctxload utility can be used for loading (creating) thesauri from a load file into the thesaurus tables, as well as dumping thesauri from the tables into output (dump) files.
The thesaurus dump files created by ctxload can be printed out or used as input for other applications. The dump files can also be used to load a thesaurus into the thesaurus tables. This can be useful for using an existing thesaurus as the basis for creating a new thesaurus.
The thesaurus used by the thesaurus operators is DEFAULT, unless a different thesaurus is explicitly called by name in the query expression.
For more information about query expressions and the thesaurus operators, see Oracle ConText Option Application Developer's Guide.
Similar to text queries and theme queries, thesauri for text queries are case-insensitive and thesauri for theme queries are case-sensitive.
For example, B is a narrower term for A. B is also in a synonym ring with terms C and D, and has two related terms, E and F. In a narrower term query for A, the following expansion occurs:
NT(A) query is expanded to {A}, {B}
Note: The query expression is not expanded to include C and D (as synonyms of B) or E and F (as related terms for B).
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |