| Oracle Context Option Administrator's Guide | Library |
Product |
Contents |
Index |
| Oracle Context Option Administrator's Guide | Library |
Product |
Contents |
Index |
![]()
![]()
The following topics are discussed in this chapter:
For more information, see "Tiles" and "Preferences" in this chapter.
The Data Store category contains separate Tiles for each of the three types of storage supported by ConText Option:
For formatted documents, ConText Option stores documents in their native format and uses filters to build temporary ASCII versions of the documents. ConText Option indexes the temporary ASCII text of the formatted document. ConText Option also uses the ASCII version to highlight query terms.
The following internal filters are provided by ConText Option:
| Internal Filters |
| Autorecognize |
| AMIPRO for Windows, version 1, 2, 3 |
| ASCII |
| HTML 1, 2, 3 |
| Lotus 1-2-3 for DOS, version 2, 3, 4, 5 and Lotus 1-2-3 for Windows, version 4, 5 |
| Lotus 1-2-3 for Windows |
| Microsoft Word for Windows, version 2 |
| Microsoft Word for Windows, version 6.x, 7.0 |
| Microsoft Word for DOS, version 5.0, 5.5 |
| Microsoft Word for MAC, version 3, 4, 5.x |
| Word Perfect for Windows, version 5.x and Word Perfect for DOS, version 5.0, 5.1 |
| Word Perfect for Windows, version 6.x and Word Perfect for DOS, version 6.0 |
| Xerox XIF for UNIX, version 5, 6 |
External filters can also be used to perform operations, such as cleaning up or uncompelling text, before the text is filtered for indexing and highlighting.
For more information about internal and external filters, see "Text Filtering Preferences" in "Text Concepts (Chapter 3)."
For more information about creating Filter preferences, see "Managing Preferences" in "Setting Up and Managing Text (Chapter 5)."
The lexer is the component that parses text and breaks it up into tokens for indexing. English and most European languages can use the same lexer because tokens (words) in those languages are delimited by blank spaces and standard punctuation (comma, period, question mark, etc.).
Japanese, Chinese, and many other Asian languages are pictorial (multi-byte) languages that cannot be tokenized in the same manner as English (single-byte). One common retrieval method for these languages is a dictionary-based lexer. The picture symbols used in the text are matched against a dictionary of known words to determine the tokens.
The Japanese and Chinese lexers also work with languages that use a 7-bit character set, such as English. As a result, ConText Option supports indexing and querying Japanese and Chinese text that also contains English text.
Note: Languages that use an 8-bit character set, such as many of the European languages, are not supported by the Japanese and Chinese lexers.
ConText Option also includes a lexer for Korean text. The Korean lexer works similarly to the Japanese and Chinese lexers by finding character patterns in the text and matching the patterns to a dictionary of terms. However, due to the significant morphological transformations that Korean verbs undergo, the Korean lexer only indexes nouns and noun phrases.
Note: The Chinese and Korean lexers are provided with a status of BETA in this release of ConText Option.
The themes generated by ConText Option are based on, but are not identical to, the content-bearing tokens in the text.
For more information about the theme lexer and theme indexing, see "Theme Indexes" in "Text Concepts (Chapter 3)."
The engine is the ConText Option component that actually creates the index for a text column. A ConText index is required before text in a column can be queried.
For example, a stem search on the verb buy expands to include its alternate verb forms, such as buys, buying, and bought, but not on the noun buyer. A search on the noun buyer would expand only to include its plural form buyers.
Since different languages have different stemming rules, stemming is language-dependent and uses wordlists that define the relationships between the words in a given language
ConText Option provides a stemmer, licensed from Xerox Corporation, that utilizes Xerox Lexical Technology to support inflectional stemming in the following languages:
For example, a fuzzy matching search on the term cat expands to include cats, calc, case.
The number of expansions generated by fuzzy matching depends on the tokens that ConText Option identified during indexing; results can vary significantly according to the tokens that were identified and indexed by ConText Option for the column. As such, fuzzy matching depends on how tokens are delimited in a given language.
Note: Fuzzy matching is designed primarily for English-language documents, but can be used, with varying degrees of success with most of the Western European languages.
Note: Soundex is designed primarily to look for matches in phonetic spellings used in English, but can be used, with varying degrees of success with most of the Western European languages.
The Soundex word list is stored in the DR_nnnnn_I1W text index table, where nnnnn is the identifier of the policy for the text index.
If Soundex is enabled for a text column, users can call Soundex in a query to expand the query. Soundex expands a query by searching the DR_nnnnn_I1W table for terms that sound similar to the specified query term.
For example, a Soundex search on the name Smith would also find the names Smythe and Smit.
Note: Soundex in ConText Option uses the same logic as the SOUNDEX function in SQL.
For more information about the SOUNDEX function in SQL, see Oracle7 Server SQL Reference.
Each stoplist can contain a maximum of 4095 words.
A Tile is the main component of a preference. When you define a preference, you specify a Tile and attributes for the Tile, as well as a value for each attribute.
Tiles are grouped into categories which identify the action performed by the Tile. There are two types of categories:
The Data Store category contains the following Tiles:
The Wordlist category contains a single Tile, GENERIC WORDLIST, which is used to:
The Reader category contains the DIRECTORY READER Tile, which is used to specify the directory where files to be loaded are stored.
The Translator category contains the following Tiles, which are used for translating files into the load file format required for text loading:
For a complete list of the predefined preferences provided by ConText Option, as well as the indexing option controlled by each preference, see "prefPredefined and Default Preferences" in "ConText Data Dictionary (Chapter 9)."
Note: If you want to create a policy that uses all of the default preferences, you can simply define the policy without specifying any preferences.
For a complete list of the default preferences provided by ConText Option, see "prefPredefined and Default Preferences" in "ConText Data Dictionary (Chapter 9)."
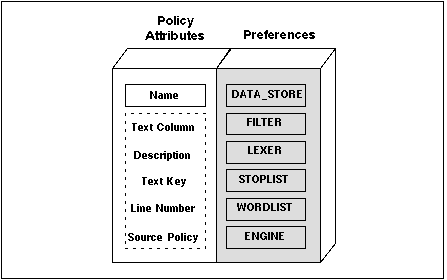 Figure 4 - 1. Diagram of a Policy
Figure 4 - 1. Diagram of a PolicyNote: A policy must exist for a column before a ConText server can create a index for the column.
Policies can be created by any ConText Option user with the CTXAPP role. Policies are stored in the ConText data dictionary. In addition to the preferences for a policy, users specify a name for the policy and the text column for the policy, and a number of other policy attributes.
The policies created by a user must be unique for the user. As such, the same policy for a user cannot be assigned to more than one column.
Table: DOC_AND_COMMENT Columns: TEXTKEY number (unique primary key) TEXTDATE date AUTHOR varchar2(50) COMMENTS varchar2(2000) (text column storing ASCII) DOC long raw (text column storing MS Word documents)
To create an index for both the COMMENT and the DOC columns, a policy must be defined for each column. The two policies might be defined as:
Policy 1 Name: I_DOC Text Column: DOC_AND_COMMENT.DOC Engine: General Purpose Engine Filter: MS-Word Lexer: General Purpose Lexer Data Store: Direct Word List: Soundex and stemming
Policy 2 Name: I_COMMENTS Text Column: DOC_AND_COMMENT.COMMENTS Engine: General Purpose Engine Filter: None Lexer: General Purpose Lexer Data Store: Direct Word List: * none *
When a query is performed, you can specify a policy name to indicate the index that is used to process the query.
This feature is particularly useful if you have English-language documents for which you want to enable both text and theme queries. To enable text and theme queries, you must create two separate policies on the column containing the documents and index the column once for each policy.
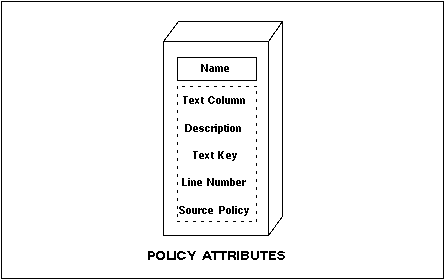 Figure 4 - 2. Policy Attributes
Figure 4 - 2. Policy Attributes
Text Column
Note: If the policy does not include a text column, the policy is a template policy, which can be used as a source policy in another policy.
Description
The description of the policy.
TextKey
The primary key column or columns (up to sixteen) for the table. This attribute is required if the policy is being assigned to a column.
Line Number
The column storing the unique identifier for the text column in a master-detail table. A master-detail table does not store a document as a single row, but rather breaks the document (identified by the textkey) into sections and stores each section in a separate row in the table. The collection of rows with the same textkey represents the whole document.
This attribute is used only for policies that include a preference for the MASTER DETAIL Tile.
Source Policy
Note: When specifying a source policy in a policy, a user can specify either their policies or CTXSYS-owned policies.
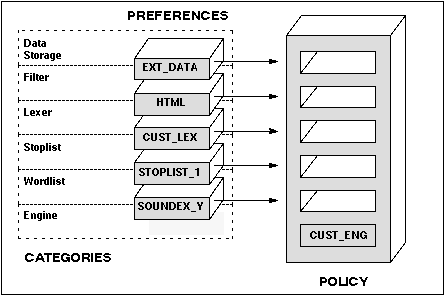 Figure 4 - 3. Preferences and Preference Categories in Policies
Figure 4 - 3. Preferences and Preference Categories in Policies
A preference can be used in more than one policy; however, two preferences from the same category cannot be used in the same policy.
Note: If you want to use the same preferences for two text columns, you must create two separate policies. The policies will be identical (having all of the same preferences), but they must have unique names and be attached to different columns. This is true whether the columns are in the same table or in different tables.
The following figure illustrates how the default preferences and user-specified preferences work together to create a complete policy.
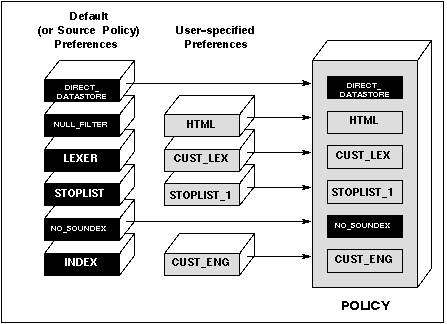 Figure 4 - 4. Default and User-specified Preferences in Policies
Figure 4 - 4. Default and User-specified Preferences in Policies
When a template policy is used as a source policy in a new policy, all of the preferences for the template policy are copied to the new policy. Any preference from the template policy can be overridden by explicitly naming a preference (for the same category) during the creation of the new policy.
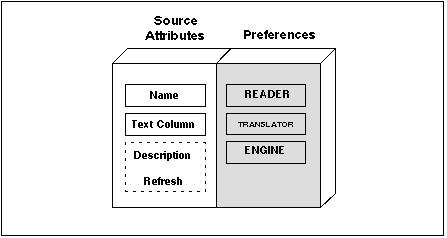 Figure 4 - 5. Diagram of a Source
Figure 4 - 5. Diagram of a SourceA source is a logical grouping of three text loader preferences (one preference for each of the supported categories), assigned to a column in the database. A source specifies the options used by ConText Option to load text automatically into a column using ctxload and ConText servers with the Loader personality.
Note: A source must exist for a column before a ConText server with the Loader personality can load text from an operating system file into the column.
Sources can be created by any ConText Option user with the CTXAPP role. Sources are stored in the ConText data dictionary. In addition to the preferences for a source, users specify a name and text column for the source. Users can also specify a description and a refresh rate for directory scanning.
The sources created by a user must be unique for the user. As such, the same source for a user cannot be assigned to more than one column.
The column in the source indicates the column to which text is loaded by ConText servers.
Note: The column must be a LONG or LONG RAW column, because load servers only supports loading text into LONG or LONG RAW columns.
A preference can be used in more than one policy; however, two preferences from the same category cannot be used in the same policy.
If a preference for one of the categories is not specified when the source is created, the default, predefined preference for the category is used in the source.
Note: All three of the loading categories have defaults; however, the default preference for the Reader category should not be used. This is because the directory specified in the default Reader preference is a generic directory specification and will not probably exist on your file system.
|
Prev Next |
Copyright © 1996 Oracle Corporation. All Rights Reserved. |
Library |
Product |
Contents |
Index |